Yu Zeng, 曾昱, Ph.D.
My research studies visual imagination: how machines can predict, generate, and understand visual change. I look for shared structure across tasks and modalities, building methods that transfer and scale. Current work spans computer vision, visual synthesis and embodied AI. I received my PhD from Johns Hopkins University and currently work at Toyota Research Institute as a researcher. Prior to this, I also worked for NVIDIA and Lightspeed Studios as a researcher and interned at Adobe Research.
News
- Our work phase-preserving diffusion is on arxiv
- Our work on one-step diffusion policy was accepted by ICML 2025 (pdf,Porject Page)
- Our work on text-to-image generation was accepted by CVPR 2024 (paper, page)
- Our work on portrait relighting was accepted by CVPR 2024 (paper , page)
- I was selected as one of the Rising Stars in AI by KAUST AI Initiative
- Our work on image inpainting was accepted by AAAI 2024 (coming soon)
Selected Articles | Full List | Google Scholar
NeuralRemaster: Phase-Preserving Diffusion for Structure-Aligned Generation. Preprint. 2025.
Y. Zeng, C. Ochoa, M. Zhou, V. M. Patel, V. Guizilini, R. McAllister
[pdf] | [Project Page]
Cosmos-Transfer. NVIDIA Tech Report.
Core contributor
[pdf] | [Project Page]
Cosmos: World Foundation Model Platform for Physical AI. NVIDIA Tech Report. Best AI and Best Overall of CES 2025
Core contributor
[pdf] | [Porject Page]
Edify Image: High-Quality Image Generation with Pixel Space Laplacian Diffusion Models. NVIDIA Tech report
Core contributor
[pdf] | [Porject Page]
One-step diffusion policy: Fast visuomotor policies via diffusion distillation. ICML. 2025.
Z. Wang, Z. Li, A. Mandlekar, Z. Xu, J. Fan, Y. Narang, L. Fan, Y. Zhu, Y. Balaji, M. Zhou, M.-Y. Liu, Y. Zeng
[pdf] | [Porject Page]
JeDi: Joint-Image Diffusion Models for Finetuning-free Personalized Text-to-Image generation. CVPR. 2024.
Yu Zeng, Vishal M. Patel, Haocheng Wang, Xun Huang, Ting-Chun Wang, Ming-Yu Liu, Yogesh Balaji
pdf | Project Page

SceneComposer: Any-Level Semantic Image Synthesis. CVPR. 2023. (Highlight, top 2.5% submission)
Yu Zeng, Zhe Lin, Jianming Zhang, Qing Liu, John Collomosse, Jason Kuen, Vishal M. Patel
pdf | Project Page

SketchEdit: Mask-Free Local Image Manipulation with Partial Sketches. CVPR. 2022.
Yu Zeng, Zhe Lin, Vishal M. Patel
pdf | Project | Demo | Code


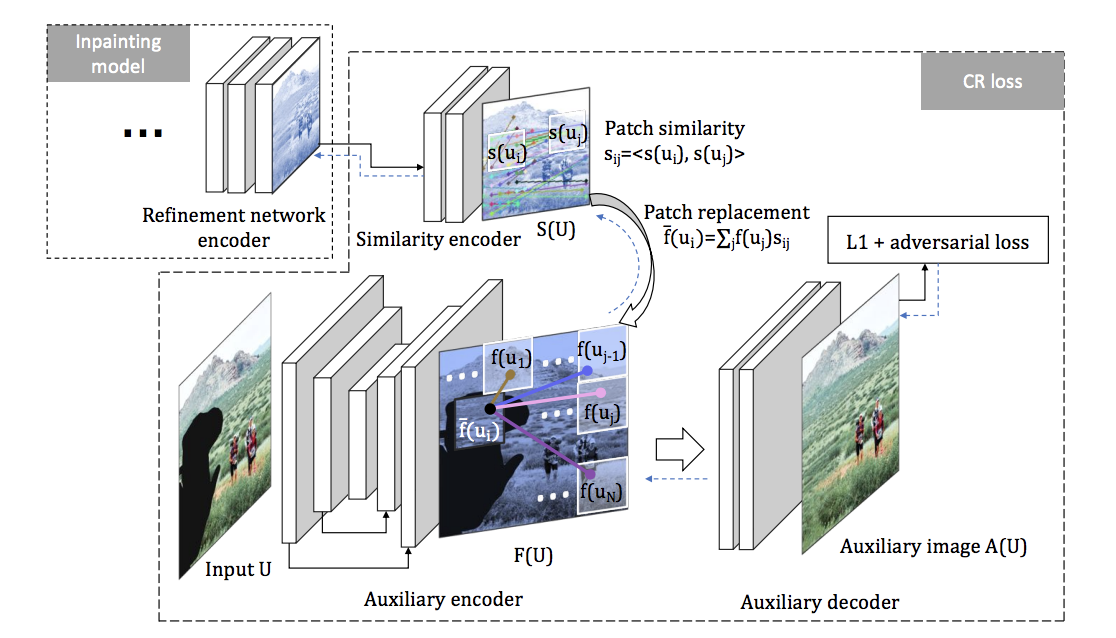
CR-Fill: Generative Image Inpainting with Auxiliary Contextual Reconstruction. ICCV. 2021.
Yu Zeng, Zhe Lin, Huchuan Lu, Vishal M. Patel
pdf | Code
High-Resolution Image Inpainting with Iterative Confidence Feedback and Guided Upsampling. ECCV. 2020.
Yu Zeng, Zhe Lin, Jimei Yang, Jianming Zhang, Eli Shechtman, Huchuan Lu
pdf | Project | Demo

Joint Learning of Saliency Detection and Weakly Supervised Semantic Segmentation. ICCV. 2019.
Zeng, Yu and Zhuge, Yunzhi and Lu, Huchuan and Zhang, Lihe
pdf | Code
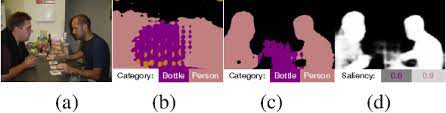
Multi-source Weak Supervision for Saliency Detection. CVPR. 2019.
Zeng, Yu and Zhuge, Yunzhi and Lu, Huchuan and Zhang, Lihe and Qian, Mingyang and Yu, Yizhou
pdf | Code
Learning to Detect Salient Object with Multi-source Weak Supervision. TPAMI. 2021.
H Zhang, Y Zeng, H Lu, L Zhang, J Li, J Qi
pdf | Code

Learning to Promote Saliency Detectors. CVPR. 2018.
Yu Zeng, Huchuan Lu, Lihe Zhang, Mengyang Feng, Ali Borji
pdf | Code
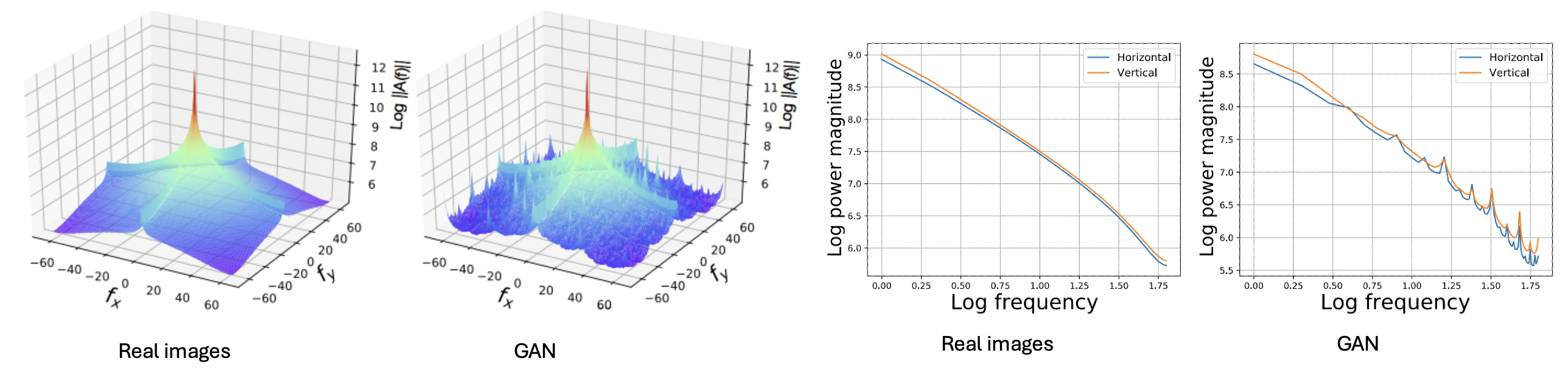
Statistics of deep generated images. arXiv preprint, 2017. [Paper]
Y. Zeng, H. Lu, and A. Borji